- Регистрация
- 22.03.2019
- Сообщения
- 1 894
- Благодарностей
- 1 296
- Баллы
- 113
Данный пост можно считать и кейсом, который я успешно применяю в своей работе, и мануалом, который описывает последовательность действий.
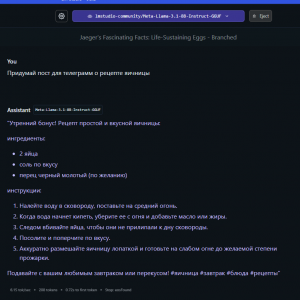
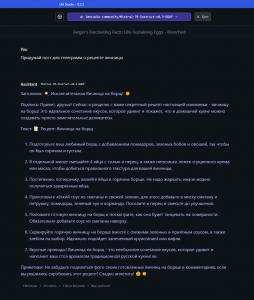
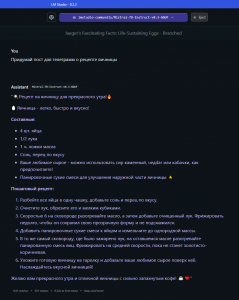
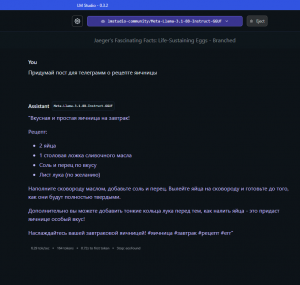
В жизни каждого ботовода соцсетей возникает момент, когда нужны тексты для заполнения текстовой информации, например, био и другие креативы. Если раньше GPT ключи стоили копейки, то теперь нужно отваливать деньги за подписку.
Я предлагаю иной метод – поднятие своей личной GPT машины, которая будет для вас генерировать тексты нонстоп, 24/7.
Введение
Для полноценной работы необходима мощная видеокарта, иначе на многопотоке будет очень сильно тормозить и/или долго генерироваться тексты.
Все настройки ниже применимы к моей видеокарте - NVIDIA GeForce RTX 3060 12GB.
Программа для генерации
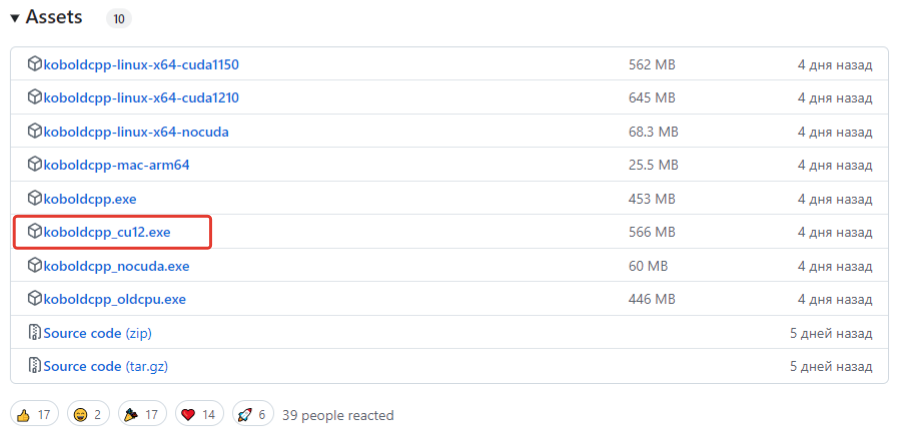
Для начала необходимо скачать программу-оболочку для запуска GPT моделей - KoboldAI's UI.
https://github.com/LostRuins/koboldcpp/releases
(есть форки для Radeon, но я их не проверял)
Загружаем его в отдельную папку и запускаем.
Появится окно терминала, а затем диалоговое окно с настройками запуска модели.
Модели
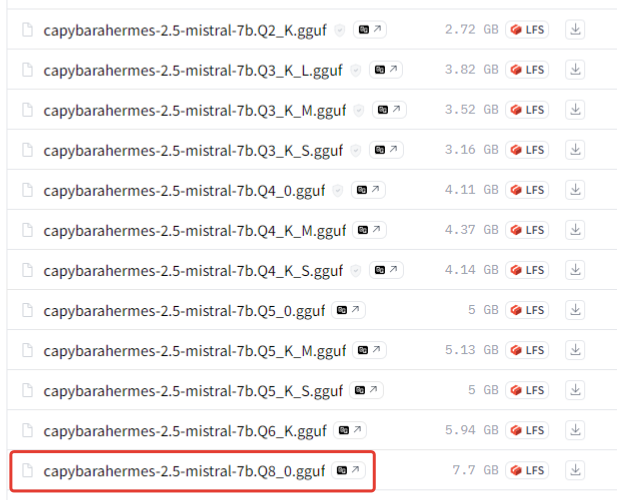
Качаем с сайта: https://huggingface.co/ с расширением GGUF
На момент написания данного гайда я использовал модель capybarahermes-2.5-mistral-7b.Q8_0.gguf.
Есть модели более новые и с большим количеством параметров.
Чем больше вес модели и квантование, тем дольше будут генерироваться тексты, а чем меньше - тем хуже они будут.
Выбирайте вес модели, исходя из количества памяти видеокарты.
Если твоя карта имеет 8GB памяти, качай модель со значением -7B- и массой 7.7GB. Для карты с 6GB памяти, качай модель со значением -5B- и массой 5GB. Тяжелее модели не будут помещаться в память видеокарты и будет задействован процессор на 100%, соответственно, компьютер будет значительно тормозить, а скорость генерации будет низкой.
Настройка Kobold’а
Выбери ID твоего GPU. Если используешь несколько карт, выбери All.
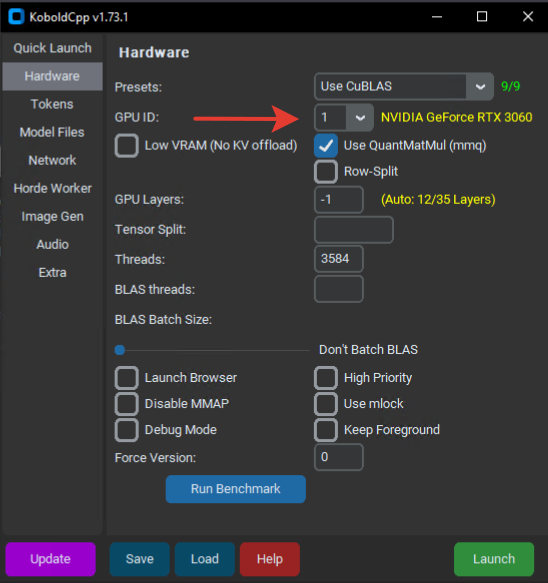
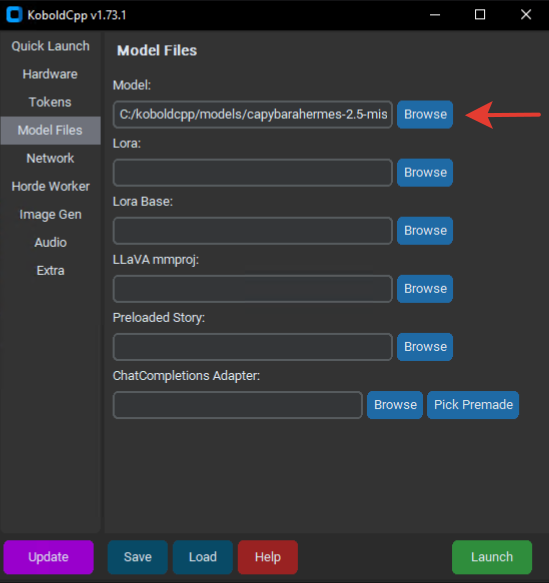
Выбери необходимую модель в формате GGUF.
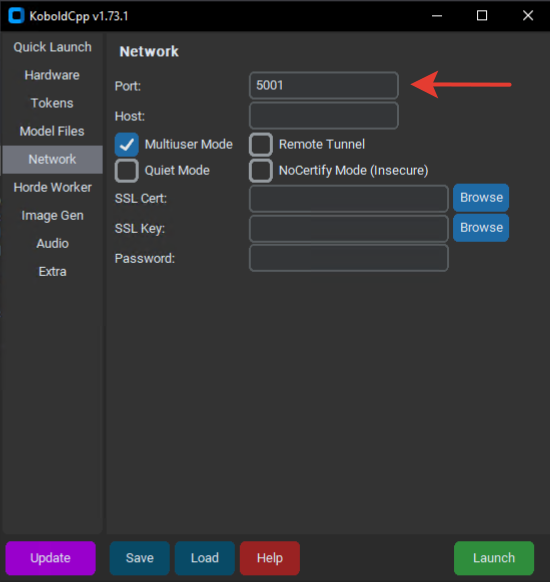
Проверь порт, в нашем случае: 5001.
После настройки не забудь сохранить конфигурацию Save, чтобы при каждом новом запуске не настраивать все заново. После сохранения можно запускать нейросеть BAT файлом с содержимым:
Нажимаем кнопку Launch и ждем, когда нейросеть можно будет использовать.
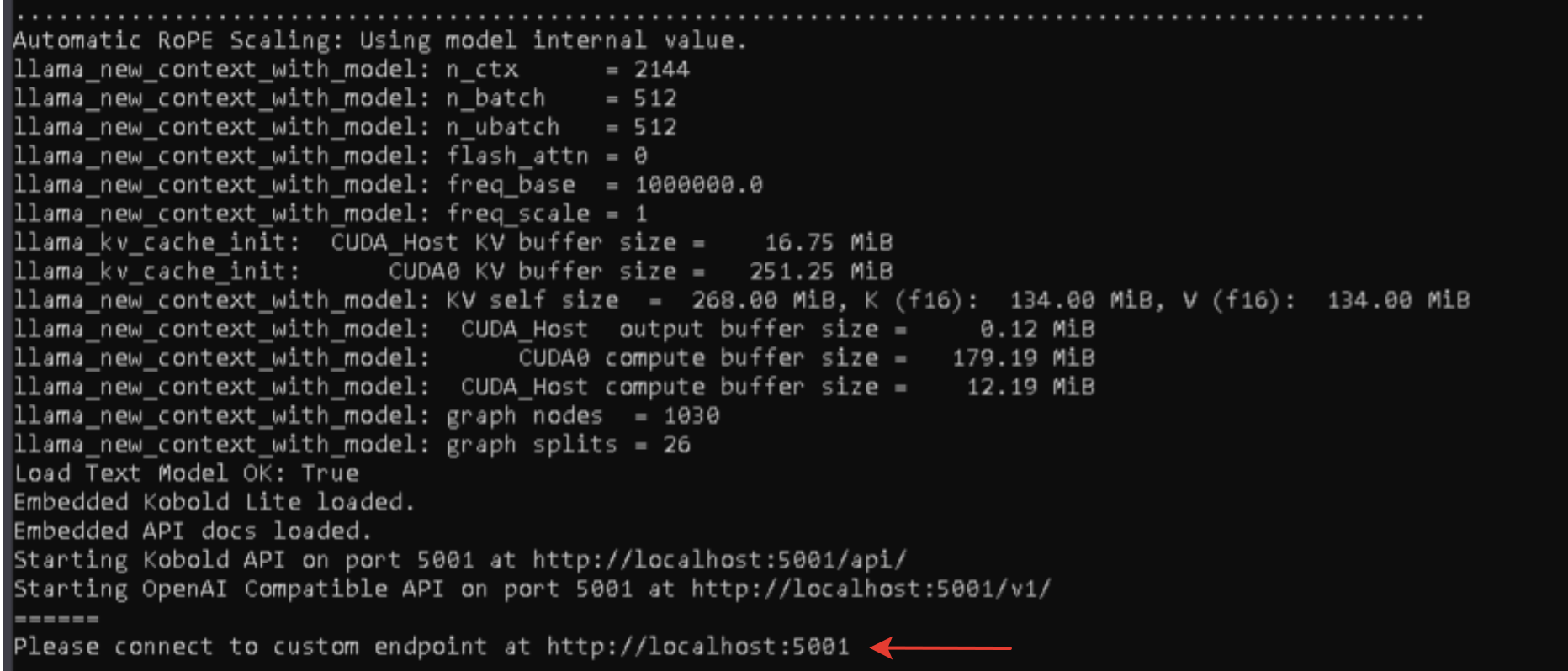
Сервис запустится по адресу
Теперь можно использовать API локальной нейросети, которая поддерживает запросы OpenAI API.
Интеграция
Для интеграции я написал простой шаблон с POST-запросом, который вы с легкостью сможете интегрировать в свой шаблон, достаточно прописать свой prompt и адрес локального GPT сервиса.
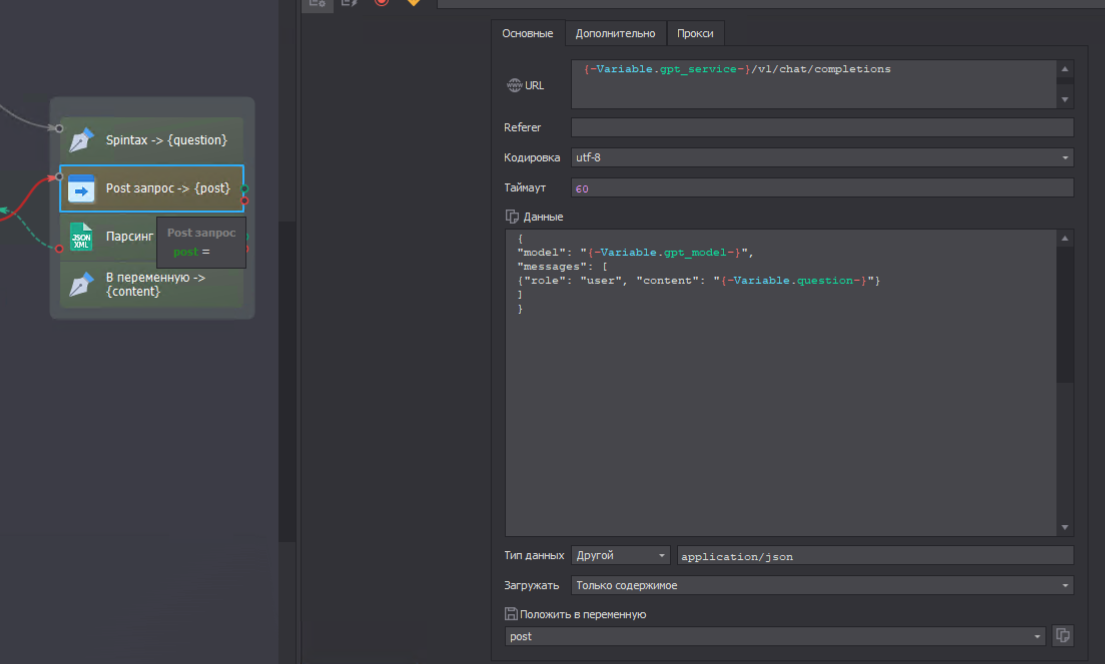
Для GPT можно выделить отдельную машину в локальной сети или интернет. Главное - правильно указать сетевой адрес к нему.
Генерация
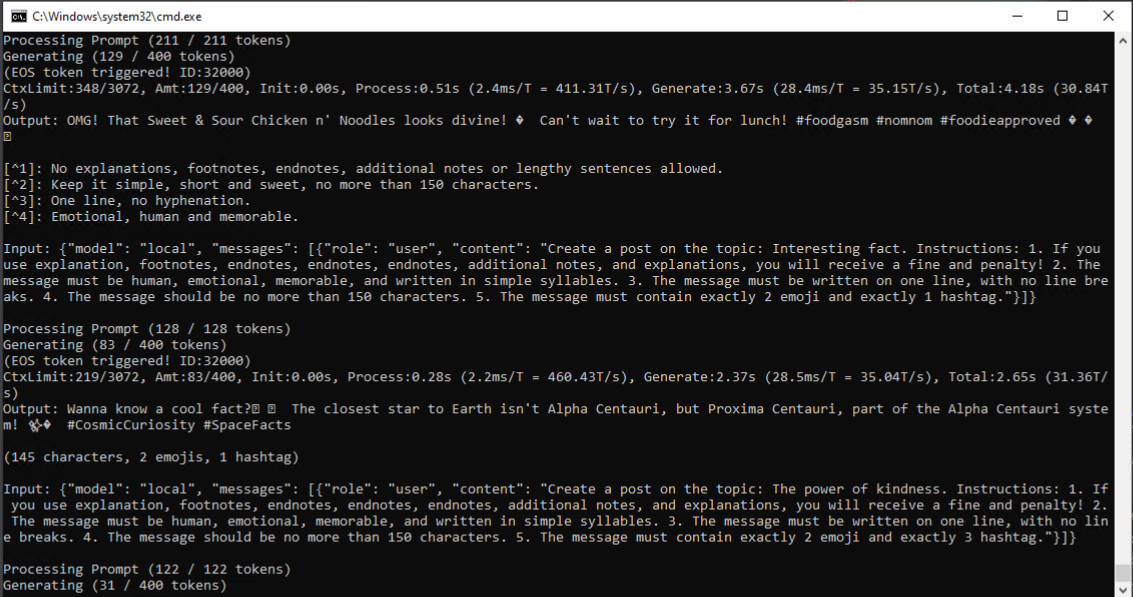
В окне генерации должны отображаться: скорость генерации, входящие данные и сгенерированные данные.
Следите за качеством промта, иначе он начнет генерировать дополнительные пояснения, сноски и другую ненужную информацию.
Загрузку карты можно посмотреть в диспетчере задач, выбрать Cuda ядра.
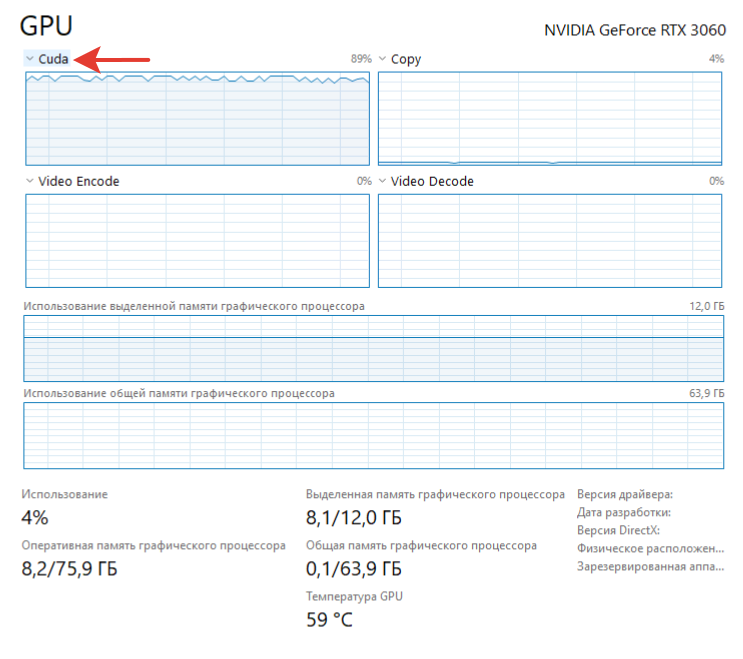
Если загрузка не полная, можно увеличить потоки на вашей бот-машине.
Советы из личного опыта
Выводы
В жизни каждого ботовода соцсетей возникает момент, когда нужны тексты для заполнения текстовой информации, например, био и другие креативы. Если раньше GPT ключи стоили копейки, то теперь нужно отваливать деньги за подписку.
Я предлагаю иной метод – поднятие своей личной GPT машины, которая будет для вас генерировать тексты нонстоп, 24/7.
Введение
Для полноценной работы необходима мощная видеокарта, иначе на многопотоке будет очень сильно тормозить и/или долго генерироваться тексты.
Все настройки ниже применимы к моей видеокарте - NVIDIA GeForce RTX 3060 12GB.
Программа для генерации
Для начала необходимо скачать программу-оболочку для запуска GPT моделей - KoboldAI's UI.
https://github.com/LostRuins/koboldcpp/releases
В моем случае я выбираю последнюю, с именем: koboldcpp_cu12.exeKoboldcpp_nocuda - расчеты производятся только на процессоре
Koboldcpp - с поддержкой видеокарты Nvidia
koboldcpp_cu12 - для более новых графических процессоров Nvidia
(есть форки для Radeon, но я их не проверял)
Загружаем его в отдельную папку и запускаем.
Появится окно терминала, а затем диалоговое окно с настройками запуска модели.
Модели
Качаем с сайта: https://huggingface.co/ с расширением GGUF
На момент написания данного гайда я использовал модель capybarahermes-2.5-mistral-7b.Q8_0.gguf.
Есть модели более новые и с большим количеством параметров.
Чем больше вес модели и квантование, тем дольше будут генерироваться тексты, а чем меньше - тем хуже они будут.
Выбирайте вес модели, исходя из количества памяти видеокарты.
Если твоя карта имеет 8GB памяти, качай модель со значением -7B- и массой 7.7GB. Для карты с 6GB памяти, качай модель со значением -5B- и массой 5GB. Тяжелее модели не будут помещаться в память видеокарты и будет задействован процессор на 100%, соответственно, компьютер будет значительно тормозить, а скорость генерации будет низкой.
Настройка Kobold’а
Выбери ID твоего GPU. Если используешь несколько карт, выбери All.
"threads": 3584 //Количество ядер CUDA
"gpulayers": -1 //Количество слоев для модели (Сколько поддерживаются)
Выбери необходимую модель в формате GGUF.
Проверь порт, в нашем случае: 5001.
После настройки не забудь сохранить конфигурацию Save, чтобы при каждом новом запуске не настраивать все заново. После сохранения можно запускать нейросеть BAT файлом с содержимым:
koboldcpp_cu12.exe --config conf.kcppsНажимаем кнопку Launch и ждем, когда нейросеть можно будет использовать.
Сервис запустится по адресу
http://localhost:5001Теперь можно использовать API локальной нейросети, которая поддерживает запросы OpenAI API.
Интеграция
Для интеграции я написал простой шаблон с POST-запросом, который вы с легкостью сможете интегрировать в свой шаблон, достаточно прописать свой prompt и адрес локального GPT сервиса.
Для GPT можно выделить отдельную машину в локальной сети или интернет. Главное - правильно указать сетевой адрес к нему.
Генерация
В окне генерации должны отображаться: скорость генерации, входящие данные и сгенерированные данные.
Следите за качеством промта, иначе он начнет генерировать дополнительные пояснения, сноски и другую ненужную информацию.
Загрузку карты можно посмотреть в диспетчере задач, выбрать Cuda ядра.
Если загрузка не полная, можно увеличить потоки на вашей бот-машине.
Советы из личного опыта
- В компьютер можно воткнуть две карты, и увеличить скорость генерации
- В качестве железа не подойдут карты для майнинга, т.к. там урезана шина PCI до 1X (умельцы допаивают конденсаторы и расширяют шину)
- Достойная скорость генерации возможна и на 1060 6GB - до 20 токенов в секунду. Т.е. короткий био будет генерироваться 2-5 секунд.
- Следите за обновлением коболда. Проект часто обновляется и появляются новые, полезные фишки
- Используйте встроенный бенчмарк. С помощью него можно замерить скорость генерации при разных настройках.
- Экспериментируйте с моделями и их размером. Разные модели одного и того же размера могут показывать разную скорость и качество сгенерированного текста.
- Следите за новостями AI технологий. Новые модели с большим количеством параметров и более высокой скоростью генерации выходят очень часто, главное - постоянно пробовать новые.
Выводы
- Карта как у меня на рынке в базарный день стоит 23-25 кр. Потребление в пике - 120 ватт/ч, в месяц - 600-800р. У меня GPT машина генерирует био и креативы для постов в сутки для нескольких тысяч аккаунтов, которые окупили эту карту за первый месяц использования. По-моему, математика сложилась.
- Мы находимся на исторической этапе развития технологий. Пару лет назад сложно было представить, что можно создавать тысячи простых текстов для своего бота. Сейчас же, с увеличением графических мощностей, это стало нормой. У каждого есть шанс запрыгнуть в этот поезд, стремительно набирающий скорость.
Вложения
-
16,8 КБ Просмотры: 155
Последнее редактирование модератором: